
Feature Importance — What Drives Tree-Model Predictions?¶
What you will learn: impurity-based importance, permutation importance, why correlated features can mislead rankings, and how to translate feature rankings into business decisions.
Why This Matters in Business¶
A high-performing model is not enough in regulated or high-stakes settings. Teams also need to answer:
Which variables drive decisions?
Are these drivers stable or artifacts?
Can we explain model behavior to operations, compliance, and leadership?
Continuity from ensembles.ipynb¶
You just learned how Random Forest and Boosting improve predictive performance. This notebook focuses on interpretation: once we trust predictive quality, which features are actually responsible for those gains?
1. Concept Map¶
2. Two Main Importance Families¶
Impurity Importance (feature_importances_)¶
Aggregates split-quality improvements across trees.
Fast and built into tree models.
Can over-credit features with many possible split points.
Permutation Importance¶
Shuffle one feature at a time on validation/test data.
Measure performance drop.
More faithful to predictive dependence, but slower.
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
from sklearn.metrics import roc_auc_score
# Synthetic dataset with correlated features to highlight ranking caveats
X, y = make_classification(
n_samples=2200,
n_features=10,
n_informative=5,
n_redundant=3,
n_repeated=0,
class_sep=1.0,
random_state=42,
)
feature_names = [f"x{i}" for i in range(X.shape[1])]
X = pd.DataFrame(X, columns=feature_names)
# Add a near-duplicate feature to show correlation instability in importances
X["x0_clone"] = X["x0"] + np.random.normal(0, 0.03, len(X))
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
rf = RandomForestClassifier(
n_estimators=350,
max_depth=None,
min_samples_leaf=2,
random_state=42,
n_jobs=-1,
)
rf.fit(X_train, y_train)
proba = rf.predict_proba(X_test)[:, 1]
auc = roc_auc_score(y_test, proba)
print(f"RandomForest AUC: {auc:.4f}")
impurity = pd.Series(rf.feature_importances_, index=X.columns, name="impurity")
perm = permutation_importance(
rf,
X_test,
y_test,
n_repeats=10,
random_state=42,
scoring="roc_auc",
n_jobs=-1,
)
perm_mean = pd.Series(perm.importances_mean, index=X.columns, name="permutation")
compare = pd.concat([impurity, perm_mean], axis=1).sort_values("permutation", ascending=False)
print("\nTop features by permutation importance:")
print(compare.head(8).round(4).to_string())
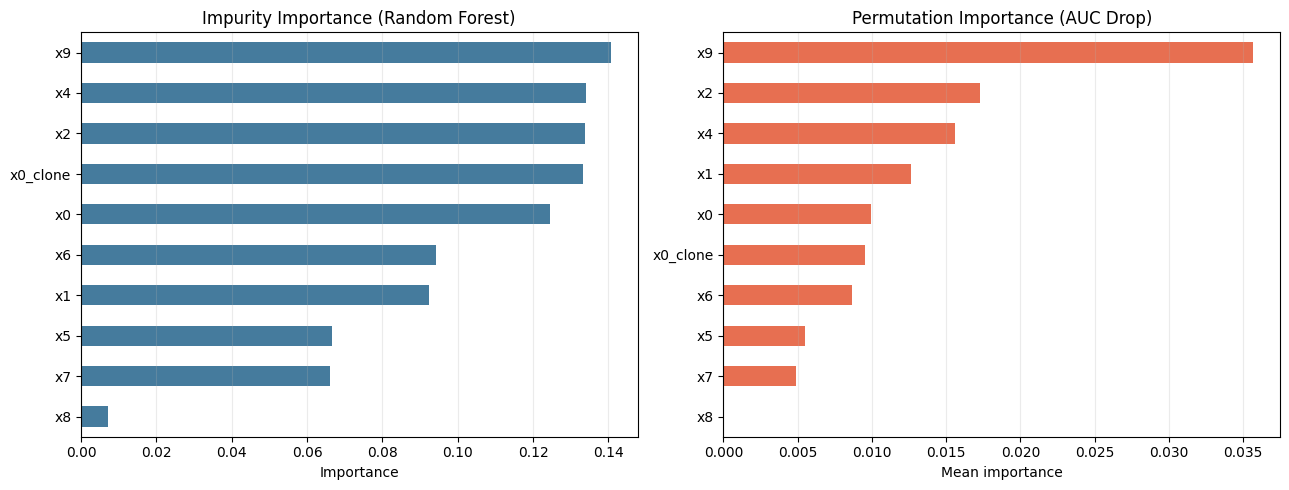
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
impurity.sort_values().tail(10).plot.barh(ax=axes[0], color="#457b9d")
axes[0].set_title("Impurity Importance (Random Forest)")
axes[0].set_xlabel("Importance")
axes[0].grid(axis="x", alpha=0.25)
perm_mean.sort_values().tail(10).plot.barh(ax=axes[1], color="#e76f51")
axes[1].set_title("Permutation Importance (AUC Drop)")
axes[1].set_xlabel("Mean importance")
axes[1].grid(axis="x", alpha=0.25)
plt.tight_layout()
plt.show()RandomForest AUC: 0.9891
Top features by permutation importance:
impurity permutation
x9 0.1407 0.0357
x2 0.1338 0.0173
x4 0.1341 0.0156
x1 0.0923 0.0126
x0 0.1244 0.0100
x0_clone 0.1333 0.0096
x6 0.0943 0.0087
x5 0.0667 0.0055
3. Optional: XGBoost Importance Types¶
If XGBoost is installed, compare weight, gain, and cover rankings.
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
try:
from xgboost import XGBClassifier
xgb = XGBClassifier(
n_estimators=220,
learning_rate=0.05,
max_depth=4,
subsample=0.9,
colsample_bytree=0.9,
eval_metric="logloss",
random_state=42,
)
xgb.fit(X_train, y_train)
booster = xgb.get_booster()
gain = booster.get_score(importance_type="gain")
weight = booster.get_score(importance_type="weight")
cover = booster.get_score(importance_type="cover")
all_feats = sorted(set(gain) | set(weight) | set(cover))
xgb_imp = pd.DataFrame({
"gain": [gain.get(f, 0.0) for f in all_feats],
"weight": [weight.get(f, 0.0) for f in all_feats],
"cover": [cover.get(f, 0.0) for f in all_feats],
}, index=all_feats)
# Normalise for visual comparison
xgb_imp = xgb_imp.div(xgb_imp.sum(axis=0), axis=1)
print("Top features by XGBoost gain:")
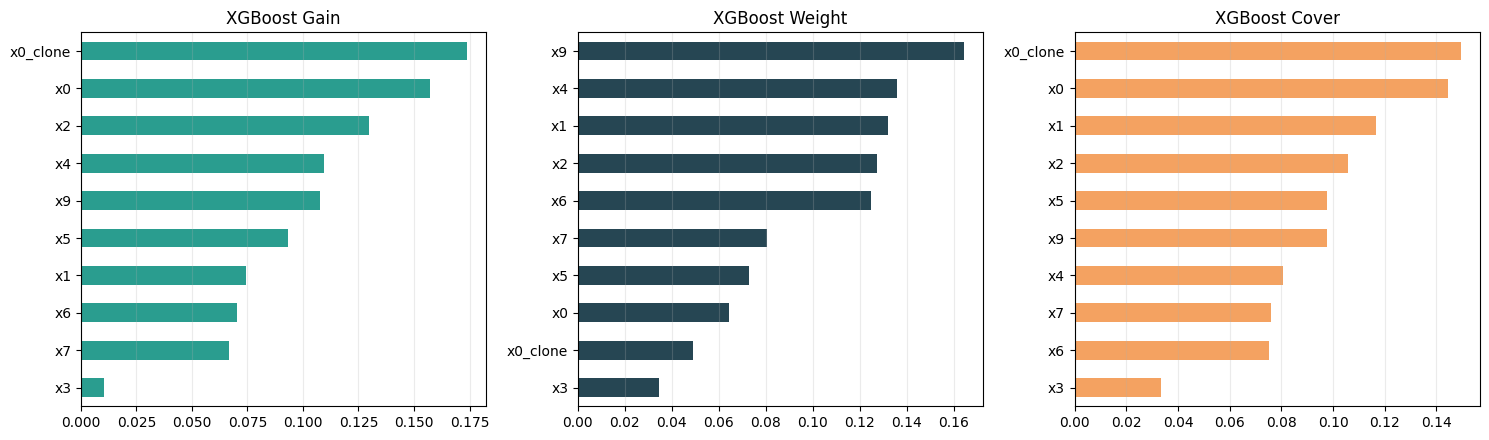
print(xgb_imp.sort_values("gain", ascending=False).head(8).round(4).to_string())
fig, axes = plt.subplots(1, 3, figsize=(15, 4.5))
xgb_imp["gain"].sort_values().tail(10).plot.barh(ax=axes[0], color="#2a9d8f")
axes[0].set_title("XGBoost Gain")
xgb_imp["weight"].sort_values().tail(10).plot.barh(ax=axes[1], color="#264653")
axes[1].set_title("XGBoost Weight")
xgb_imp["cover"].sort_values().tail(10).plot.barh(ax=axes[2], color="#f4a261")
axes[2].set_title("XGBoost Cover")
for ax in axes:
ax.grid(axis="x", alpha=0.25)
plt.tight_layout()
plt.show()
except Exception as exc:
print(f"XGBoost section skipped: {type(exc).__name__}: {exc}")Top features by XGBoost gain:
gain weight cover
x0_clone 0.1739 0.0488 0.1494
x0 0.1572 0.0644 0.1445
x2 0.1297 0.1273 0.1057
x4 0.1096 0.1360 0.0805
x9 0.1078 0.1643 0.0976
x5 0.0931 0.0730 0.0977
x1 0.0745 0.1319 0.1167
x6 0.0701 0.1246 0.0752
4. Try It in the Browser¶
Use a tiny feature-score table and identify the strongest signal.
scores = {
"transaction_amount": 0.34,
"country_risk": 0.22,
"night_hour": 0.17,
"merchant_age_days": 0.05,
"browser_language": 0.02,
}
ranked = sorted(scores.items(), key=lambda x: x[1], reverse=True)
print("Feature ranking (highest to lowest):")
for i, (name, s) in enumerate(ranked, 1):
print(f"{i}. {name:<20} {s:.2f}")
print("\nTop-2 candidate drivers:", [r[0] for r in ranked[:2]])Knowledge Check¶
Why can impurity-based importance be misleading?¶
CheckPermutation importance is best interpreted as:¶
CheckCommon Pitfalls¶
Exercises¶
Exercise 1 - Ranking stability¶
Train Random Forests with 10 different random seeds and measure rank variance of top-5 features.
Exercise 2 - Correlation stress test¶
Add two synthetic duplicates of a top feature and compare impurity vs permutation ranking changes.
Exercise 3 - Business narrative¶
Write a 5-line stakeholder explanation for the top-3 features in fraud detection terms.
Summary
Use impurity importance for speed and initial screening.
Use permutation importance to validate real predictive dependence.
Correlated features can split credit and confuse interpretation.
Translate rankings into business actions with governance checks.

What’s Next - Lab: Fraud Detection¶
You now have the interpretation toolkit. In trees_lab.ipynb, you will apply tree ensembles and feature-importance reasoning end-to-end in a fraud-detection workflow with business metrics.
%matplotlib inline
# Exercise starter cell
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
# Your code here