
Bagging, Random Forests, and XGBoost¶
What you will learn: why single trees are unstable, how bagging reduces variance, how random forests add feature randomness, and how boosting methods reduce bias through sequential learning.
Why Ensembles Matter in Business¶
A single decision tree is easy to explain but often unstable. In fraud detection, credit scoring, and churn models, this instability creates business risk.
Ensembles combine many weak or unstable learners so predictions become more robust.
Continuity from decision_trees.ipynb¶
In the previous notebook, you saw that deeper trees can overfit and single trees are unstable. This chapter fixes that by combining trees intelligently.
1. Core Ideas¶
Bagging (Bootstrap Aggregating)¶
Train many base models on bootstrap-resampled datasets.
Aggregate predictions:
classification: majority vote
regression: average
Main effect: reduces variance.
Random Forest¶
Bagging + random subset of features at each split.
De-correlates trees and usually improves test performance.
Boosting¶
Train weak learners sequentially.
Each new learner focuses on mistakes of prior learners.
Main effect: reduces bias.
| Method | Training style | Primary gain | Typical risk |
|---|---|---|---|
| Bagging | Parallel | Variance reduction | More compute |
| Random Forest | Parallel + feature randomness | Strong tabular baseline | Less interpretable than one tree |
| Boosting | Sequential | Bias reduction | Overfitting if under-regularised |
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from collections import Counter
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, value=None):
self.feature = feature
self.threshold = threshold
self.left = left
self.right = right
self.value = value
class DecisionTree:
"""Simple entropy-based tree used as a base learner for the custom RF."""
def __init__(self, max_depth=3, min_samples_split=2):
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.root = None
def fit(self, X, y, feature_indices):
self.feature_indices = feature_indices
self.root = self._grow_tree(X, y, depth=0)
def _grow_tree(self, X, y, depth):
n_samples, _ = X.shape
if depth >= self.max_depth or n_samples < self.min_samples_split or len(np.unique(y)) == 1:
return Node(value=Counter(y).most_common(1)[0][0])
best_feature, best_threshold = self._best_split(X, y)
if best_feature is None:
return Node(value=Counter(y).most_common(1)[0][0])
left_idx = X[:, best_feature] <= best_threshold
right_idx = ~left_idx
left = self._grow_tree(X[left_idx], y[left_idx], depth + 1)
right = self._grow_tree(X[right_idx], y[right_idx], depth + 1)
return Node(best_feature, best_threshold, left, right)
def _best_split(self, X, y):
best_gain = -1
best_feature, best_threshold = None, None
for feature in self.feature_indices:
for threshold in np.unique(X[:, feature]):
left_idx = X[:, feature] <= threshold
right_idx = ~left_idx
if np.sum(left_idx) == 0 or np.sum(right_idx) == 0:
continue
gain = self._information_gain(y, left_idx, right_idx)
if gain > best_gain:
best_gain = gain
best_feature = feature
best_threshold = threshold
return best_feature, best_threshold
def _information_gain(self, y, left_idx, right_idx):
n = len(y)
n_l, n_r = np.sum(left_idx), np.sum(right_idx)
parent_entropy = self._entropy(y)
child_entropy = (n_l / n) * self._entropy(y[left_idx]) + (n_r / n) * self._entropy(y[right_idx])
return parent_entropy - child_entropy
@staticmethod
def _entropy(y):
hist = np.bincount(y)
ps = hist / len(y)
return -np.sum([p * np.log2(p) for p in ps if p > 0])
def predict(self, X):
return np.array([self._traverse_tree(x, self.root) for x in X])
def _traverse_tree(self, x, node):
if node.value is not None:
return node.value
if x[node.feature] <= node.threshold:
return self._traverse_tree(x, node.left)
return self._traverse_tree(x, node.right)
class RandomForest:
"""Custom RF: bootstrap + random feature subsets + majority vote."""
def __init__(self, n_trees=25, max_depth=3, min_samples_split=2, n_features=None, random_state=42):
self.n_trees = n_trees
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.n_features = n_features
self.rng = np.random.default_rng(random_state)
self.trees = []
def fit(self, X, y):
self.trees = []
n_samples, n_features_total = X.shape
n_features = self.n_features or int(np.sqrt(n_features_total))
for _ in range(self.n_trees):
idx = self.rng.choice(n_samples, n_samples, replace=True)
X_sample, y_sample = X[idx], y[idx]
feature_indices = self.rng.choice(n_features_total, n_features, replace=False)
tree = DecisionTree(self.max_depth, self.min_samples_split)
tree.fit(X_sample, y_sample, feature_indices)
self.trees.append(tree)
def predict(self, X):
predictions = np.array([tree.predict(X) for tree in self.trees])
return np.apply_along_axis(lambda x: Counter(x).most_common(1)[0][0], axis=0, arr=predictions)
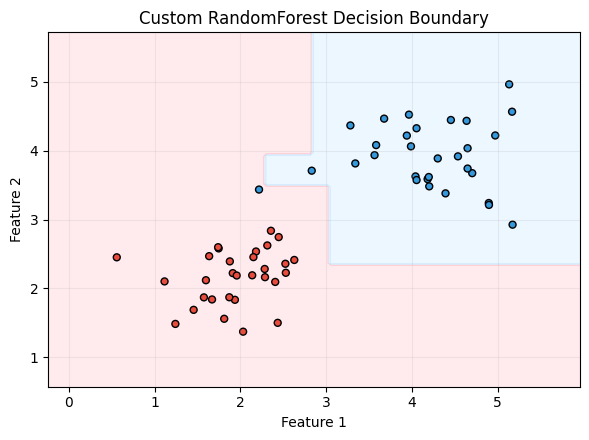
def plot_decision_boundary(X, y, model, title):
x_min, x_max = X[:, 0].min() - 0.8, X[:, 0].max() + 0.8
y_min, y_max = X[:, 1].min() - 0.8, X[:, 1].max() + 0.8
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.05), np.arange(y_min, y_max, 0.05))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
plt.figure(figsize=(6, 4.5))
plt.contourf(xx, yy, Z, alpha=0.25, cmap=ListedColormap(['#ffb3ba', '#bae1ff']))
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap=ListedColormap(['#e74c3c', '#3498db']), s=25)
plt.title(title)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.grid(alpha=0.2)
plt.tight_layout()
plt.show()
np.random.seed(42)
X = np.vstack([
np.random.normal([2, 2], 0.55, (120, 2)),
np.random.normal([4, 4], 0.55, (120, 2))
])
y = np.array([0] * 120 + [1] * 120)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
rf_custom = RandomForest(n_trees=25, max_depth=4, n_features=2, random_state=42)
rf_custom.fit(X_train, y_train)
y_pred_custom = rf_custom.predict(X_test)
print(f"Custom RandomForest test accuracy: {accuracy_score(y_test, y_pred_custom):.4f}")
plot_decision_boundary(X_test, y_test, rf_custom, 'Custom RandomForest Decision Boundary')
Custom RandomForest test accuracy: 0.9833
2. Practical Benchmark: Single Tree vs Bagging vs Random Forest vs Boosting¶
We compare generalisation, not training accuracy.
same split and noisy dataset (
make_moons)models: single tree, bagging, random forest, gradient boosting
optional XGBoost with fallback if package is unavailable
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, GradientBoostingClassifier
X, y = make_moons(n_samples=800, noise=0.28, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
models = {
'Single Tree': DecisionTreeClassifier(max_depth=5, random_state=42),
'Bagging (50 trees)': BaggingClassifier(
estimator=DecisionTreeClassifier(max_depth=5, random_state=42),
n_estimators=50,
random_state=42
),
'Random Forest (200 trees)': RandomForestClassifier(
n_estimators=200,
max_depth=5,
random_state=42
),
'Gradient Boosting': GradientBoostingClassifier(
n_estimators=200,
learning_rate=0.05,
max_depth=2,
random_state=42
)
}
scores = {}
for name, model in models.items():
model.fit(X_train, y_train)
scores[name] = accuracy_score(y_test, model.predict(X_test))
try:
from xgboost import XGBClassifier
xgb = XGBClassifier(
n_estimators=250,
learning_rate=0.05,
max_depth=3,
subsample=0.9,
colsample_bytree=0.9,
random_state=42,
eval_metric='logloss'
)
xgb.fit(X_train, y_train)
scores['XGBoost (optional)'] = accuracy_score(y_test, xgb.predict(X_test))
except Exception as exc:
print(f"XGBoost skipped: {type(exc).__name__}: {exc}")
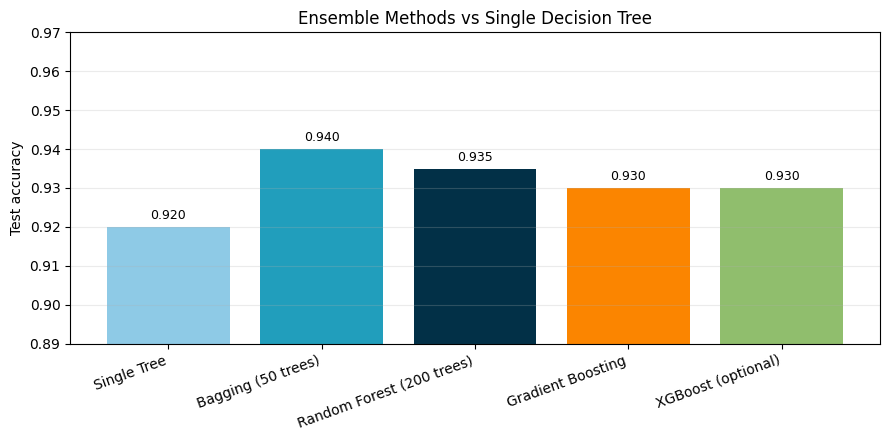
print('Test accuracy comparison:')
for k, v in sorted(scores.items(), key=lambda kv: kv[1], reverse=True):
print(f" {k:<28} {v:.4f}")
plt.figure(figsize=(9, 4.5))
names = list(scores.keys())
vals = [scores[n] for n in names]
bars = plt.bar(names, vals, color=['#8ecae6', '#219ebc', '#023047', '#fb8500', '#90be6d'][:len(names)])
plt.ylim(max(0.75, min(vals) - 0.03), min(1.0, max(vals) + 0.03))
plt.ylabel('Test accuracy')
plt.title('Ensemble Methods vs Single Decision Tree')
plt.xticks(rotation=20, ha='right')
for b, v in zip(bars, vals):
plt.text(b.get_x() + b.get_width() / 2, v + 0.002, f"{v:.3f}", ha='center', fontsize=9)
plt.grid(axis='y', alpha=0.25)
plt.tight_layout()
plt.show()
Test accuracy comparison:
Bagging (50 trees) 0.9400
Random Forest (200 trees) 0.9350
Gradient Boosting 0.9300
XGBoost (optional) 0.9300
Single Tree 0.9200
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class AdaBoostFromScratch:
"""Binary AdaBoost with decision stumps and weighted errors."""
def __init__(self, n_estimators=40):
self.n_estimators = n_estimators
self.alphas = []
self.models = []
def fit(self, X, y_pm1):
n_samples = X.shape[0]
w = np.ones(n_samples) / n_samples
self.alphas, self.models = [], []
for _ in range(self.n_estimators):
stump = DecisionTreeClassifier(max_depth=1, random_state=42)
stump.fit(X, y_pm1, sample_weight=w)
pred = stump.predict(X)
err = np.sum(w * (pred != y_pm1))
err = np.clip(err, 1e-10, 1 - 1e-10)
alpha = 0.5 * np.log((1 - err) / err)
w *= np.exp(-alpha * y_pm1 * pred)
w /= np.sum(w)
self.models.append(stump)
self.alphas.append(alpha)
def predict(self, X):
scores = np.zeros(X.shape[0])
for alpha, model in zip(self.alphas, self.models):
scores += alpha * model.predict(X)
return np.sign(scores)
X, y = make_classification(
n_samples=900,
n_features=12,
n_informative=6,
n_redundant=2,
class_sep=1.1,
random_state=42
)
y_pm1 = 2 * y - 1
X_train, X_test, y_train, y_test = train_test_split(
X, y_pm1, test_size=0.25, random_state=42, stratify=y_pm1
)
ada = AdaBoostFromScratch(n_estimators=50)
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
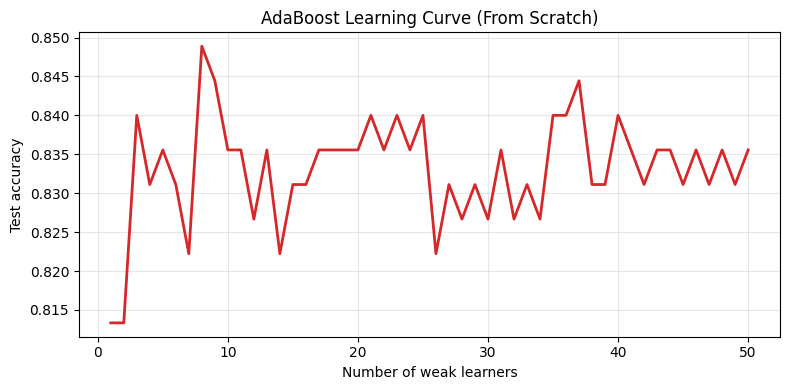
print(f"AdaBoost (from scratch) test accuracy: {accuracy_score(y_test, y_pred):.4f}")
acc_curve = []
for m in range(1, len(ada.models) + 1):
scores = np.zeros(X_test.shape[0])
for alpha, model in zip(ada.alphas[:m], ada.models[:m]):
scores += alpha * model.predict(X_test)
acc_curve.append(accuracy_score(y_test, np.sign(scores)))
plt.figure(figsize=(8, 4))
plt.plot(range(1, len(acc_curve) + 1), acc_curve, color='#d62828', lw=2)
plt.xlabel('Number of weak learners')
plt.ylabel('Test accuracy')
plt.title('AdaBoost Learning Curve (From Scratch)')
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
AdaBoost (from scratch) test accuracy: 0.8356
3. Try It in the Browser¶
Build a mini bagging vote from hand-written model predictions.
from collections import Counter
weak_model_preds = [
[1, 0, 1, 1, 0, 0],
[1, 1, 1, 1, 0, 0],
[0, 0, 1, 1, 0, 1],
[1, 0, 1, 0, 0, 0],
[1, 0, 1, 1, 1, 0],
]
n_customers = len(weak_model_preds[0])
ensemble_vote = []
for i in range(n_customers):
votes = [m[i] for m in weak_model_preds]
ensemble_vote.append(Counter(votes).most_common(1)[0][0])
print('Weak model predictions (rows)')
for row in weak_model_preds:
print(row)
print('\nEnsemble majority-vote prediction:')
print(ensemble_vote)Knowledge Check¶
What is the main reason Random Forest usually beats a single deep tree?¶
CheckWhich statement best describes boosting?¶
CheckCommon Pitfalls¶
Exercises¶
Exercise 1 - Variance reduction check¶
Train 20 independent DecisionTreeClassifier(max_depth=None) models with different random seeds and measure test accuracy variance. Then compare with RandomForestClassifier.
Exercise 2 - Boosting tuning¶
Tune n_estimators and learning_rate for Gradient Boosting on a noisy binary dataset. Plot validation accuracy vs estimator count.
Exercise 3 - Explainability trade-off¶
Compare one shallow tree and one random forest on the same data. Write a short note on interpretability vs performance.
Summary
Bagging averages many models to reduce variance.
Random Forest adds feature randomness to de-correlate trees and improve robustness.
Boosting learns sequentially from errors, often improving bias.
Ensemble models are usually stronger than a single tree on tabular business datasets.

What’s Next - Feature Importance¶
Now that you can train strong tree ensembles, the next notebook focuses on feature importance: which variables drive predictions, and how to avoid misleading interpretations when features are correlated.
Proceed to feature_importance.ipynb.
%matplotlib inline
# Exercise starter cell
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# Your code here